Data Projects
Data Projects
Predicting passenger survival aboard Titanic - Kaggle competition
- Link: Kaggle notebook
- Goal: Predict passenger survival aboard the Titanic.
- Context: Project done as a part of the Kaggle machine learning competition
- Deliverables:
- Placed in the top 1.3% globally with a bagged random forest model (with conditionally imputed trees)
- Performed EDA and engineered nine new features, five of which were highly correlated with Survival
- Evaluated various models with training accuracy as high as 83.3% under a 10-fold cross validation
- Champion model: Bagged random forest
- Test accuracy: 81.334%
- CV standard deviation: 0.06%
Topological Data Analysis to classify shapes based on topological features
- Link: Blog posts - Part 1, Part 2, Part 3
- Goal: Build a topological machine learning pipeline that classifies shapes based on topological features.
- Context: Project done as a part of doctoral comprehensive exams on topological data analysis.
- Deliverables:
- Implemented a topological ML pipeline that
- Extracted underlying topological information from point clouds (persistence barcodes).
- Trained a random forest classifier on the topological features.
- Achieved considerable dimension reduction by a factor of $\approx 1/N$, while retaining competitive performance.
- Out-of-bag accuracy scores:
- Synthetic data: 100%
- Real life data: 82.5% (Source: Princeton computer vision course)
- Implemented a topological ML pipeline that
Robust Subspace Recovery
- Link: GitHub
- Goal: Extract a smaller dimensional subspace that contains “enough” points of a partitioned point cloud $\mathcal{X}$
- Context: Project done as a part of doctoral comprehensive exams on quiver representation theory
- Deliverables:
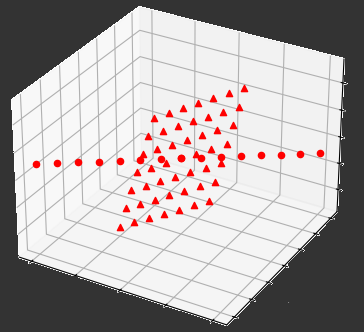
- Implemented an algorithm that extracted a smaller linear subspace that contains enough points of $\mathcal{X}$
- Furthermore, the extraction was simultaneous in the following sense:
- $\mathcal{X}$ is formed by concatenating various point clouds into a single matrix
- The extracted subspace contains enough points of this concatenation
- Helps mitigate cases where such a recovery is not possible given only a single factor of the concatenation.
Predicting user churn with Waze data
- Link: GitHub
- Goal: Predict user churn behavior by analyzing data collected from Waze app.
- Data Source: Waze app (via Google)
- Context: Project done as a part of an advanced data analytics certification powered by Google.
- Deliverables:
- EDA findings that indicated churn trends based on distance driven.
- Engineered features that improved predictive power of the champion model.
- Built regression and machine learning models that predicted user churn behavior.
- Champion model: XGB-classifier
- Accuracy: 81%
- Recall: 16.5%
- Champion model: XGB-classifier
Harvest the sun! - Optimizing solar practicality across mainland US
- Link: Blog post
- Goal: Rank states/zip based on the socio-economic feasibility of installing solar panels to the median house.
- Data source: Project sunroof, Google.
- Context: Project done as a part of a data analytics certification powered by Google.
- Deliverables:
- Engineered three indices that captured unique aspects of solar feasibility.
- Impact index: Captures the impact in terms of CO2 offset resulted by one solar installation.
- Economical index: Captures the short term set-up costs and hurdles for solar installation.
- Savings index: Captures the long term savings that result from solar installation.
- Designed a Tableau dashboard to communicate findings.
- Engineered three indices that captured unique aspects of solar feasibility.
Nucleation of market bubbles
- Link: GitHub
- Goal: Adapt physical nucleation theory (JMAK) to the financial sector to predict market bubbles
- Data source: FRED economic data
- Context: Project done as a part of undergraduate senior capstone project
- Deliverables:
- Recontextualized the Avrami-JMAK equations, from physical nucleation theory, to the financial setting.
- Fitted model to 2007 housing data to identify scale-invariant indicators of formation/collapse of bubbles.
- Model RMS error: 12% over prior bubble phases of stocks from selected sectors.
ML and programming
Quantum computing and algorithms (In progress)
- Link: TBD
- Goal: Understand theory and contemporary applications of quantum computing using Qiskit.py
- Deliverables: All or some of the following:
- Recontextualize hermitian linear algebra and algebraic geometry over $\mathbb{C}$ into quantum computing language.
- Learn to use Qiskit
- Implement quantum gates and some algorithms from scratch (ambitious)
Solving mazes and simulating cycles - a saga of genetic algorithm
- Link: GitHub - Maze Solver, ODE Parameter Estimator. Blog post - coming soon
- Goal: Implement agents guided by the genetic algorithm to -
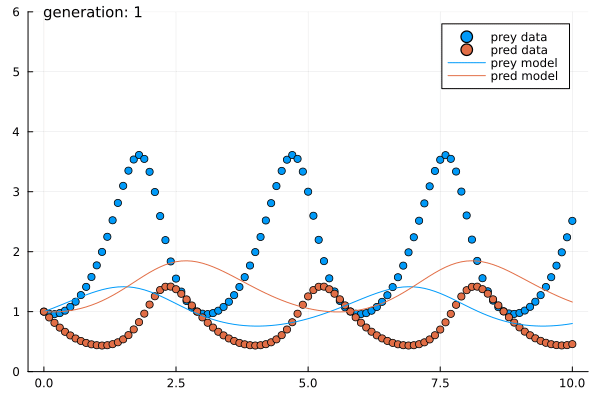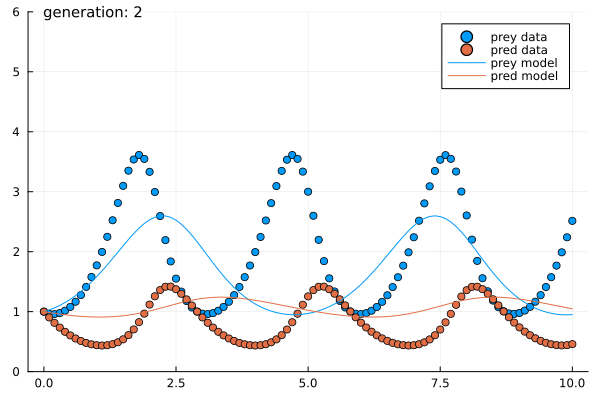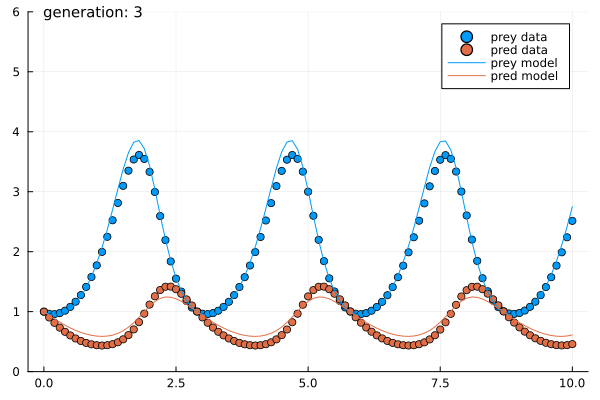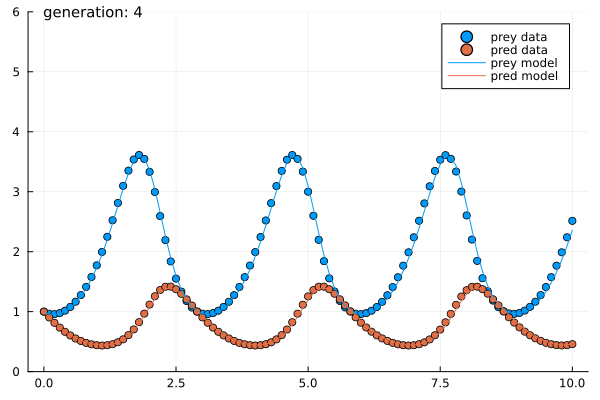
- Solve a randomly generated maze
- Estimate the parameters of a coupled system of Ordinary Differential Equations
- Deliverables: Developed agents (with hereditary genes) that
- Solved a randomly generated maze in $O(M*N^2)$ time
- Estimated parameters of the Predator-Prey system within $5$ generations of $5$ agents each.
- Presented to the right is a sample run.
Fractal engine
- Link: Blog post - L systems and fractal generation
- Goal: Develop a fractal engine using Lindenmeyer rulesets for fractal generation
- Deliverables:
- Implemented an engine that takes in the lindenmeyer ruleset of the fractal and draws it on the canvas
- The drawing is further beautified and animated by the wonderful open source library manim
- Here is a sample (that is also my favorite):
Numeripy - python package
- Link: PyPi, GitHub
- Goal: Develop a python package containing numerical ODE solvers and matrix methods
- Deliverables:
numeripy.ODE_solversoffers numerical ODE solvers that offer robust precision control and flexibilitynumeripy.matrix_methodsoffers matrix methods aimed for use in numerical linear algebra tools- In addition,
numeripy.latexit()generates latex formatted tables ready to be pasted into a LaTeX document